この記事は Holmes Advent Calendar 2020 - Qiita 9 日目の記事です。
こんにちは。 Holmesでスクラムマスターをしている吾郷です。
今日はチームで行ったスプリントプランニング改善について振り返ります。 また、それにあたって最近アップデートがあったスクラムガイドも参考にしましたので、そちらにも触れながら自身の所属チームのHudsonのスプリントプランニングについて紹介します。
スプリントプランニング改善したい!という意見が出てきたのでチーム内でプランニングの目的や、やることを再定義する機会を設けました。
背景
自分が参加しているスクラムチームはHudsonといいます。 今年の1月からHudsonというチームで活動を続けています。 この一年の間で様々なTRYが生まれ、各イベントやスプリントで実施してきました。
課題
現在、スプリントプランニング内での実施項目が多く、アジェンダが曖昧。 (特にスクラムガイド2017内でいうプランニング二部) そのため、時間が足りなくなり、目的とするスプリントバックログ作成までできていない。
やったこと
スクラムガイドがアップデートされていい機会なので、きちんとガイドに沿うために読み合わせをする。 30分でトピック1からトピック3を読み、それぞれ気づいたことを共有・ディスカッション
結果
今回は、普段使用しているオンラインホワイトボードのmiroに整理したアジェンダを作ってみました。 結果としてはHudsonチームでは以下の分割・内容でプランニングを進めてみることにしました。 時間はトピック1と2に30分ずつ、トピック3に1時間を目安にしています。
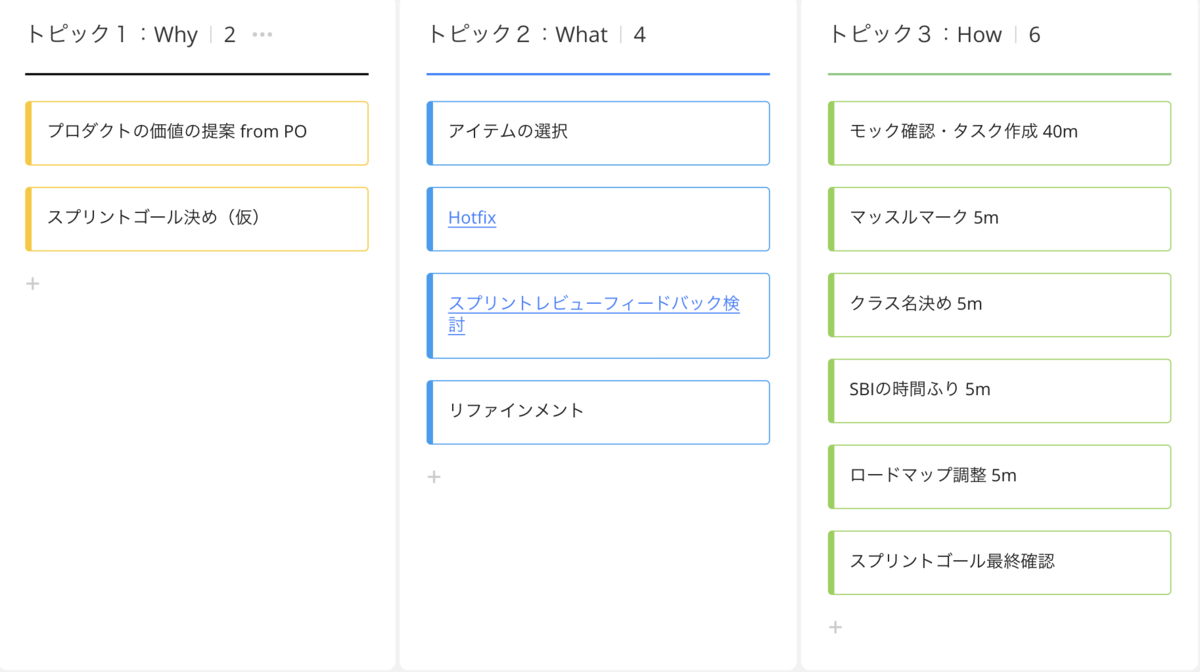
トピック1:Why
プロダクトの価値の提案 from PO
基本的にはスクラムガイド2020のトピック1をそのまま採用しています。 まずはPOからプロダクトバックログの状況などを共有してもらいながら、どういったことがこのスプリントでできるとよいかを提案してもらい、 その提案をもとにスクラムチームでどういうスプリントゴールを設定するか議論します。
スプリントゴール決め(仮)
一通り意見が固まれば、仮案としてのスプリントゴールとして次のトピックに進んでいきます。
トピック2:What
アイテムの選択
直近のベロシティを確認しながら、どのアイテムを選択するかを話し合います。 また必要であればPBIをスプリントのサイズに分割したり、実装についての認識合わせをしたりといったリファインメントも行います。
Hotfix
また、現在HolmesではHotfixチケットについて、専任チームではなく状況に応じて各チームで対応を行っています。 そのため、対応すべきHotfixがなにかの認識合わせも行います。
スプリントレビューフィードバック検討
さらに、このトピック2でスプリントレビューでいただいたフィードバックの対応方針検討も行います。
トピック3:How
ここからは、各スクラムチームで色が分かれるところになると思いますので、参考にしていただけると幸いです。 基本的には、スプリントバックログを作成していく時間になります。 せっかくなのでアジェンダ内のTRYについても少し触れながら流れを説明します。 気になるアジェンダなどありましたら、ぜひコメントしていただければと思います。
モック確認・タスク作成
モックを確認しながら、現時点で必要な作業をまずは付箋に洗い出していきます。 この際、モックも必要なことがわかれば付箋にして作成していきます。
マッスルマーク
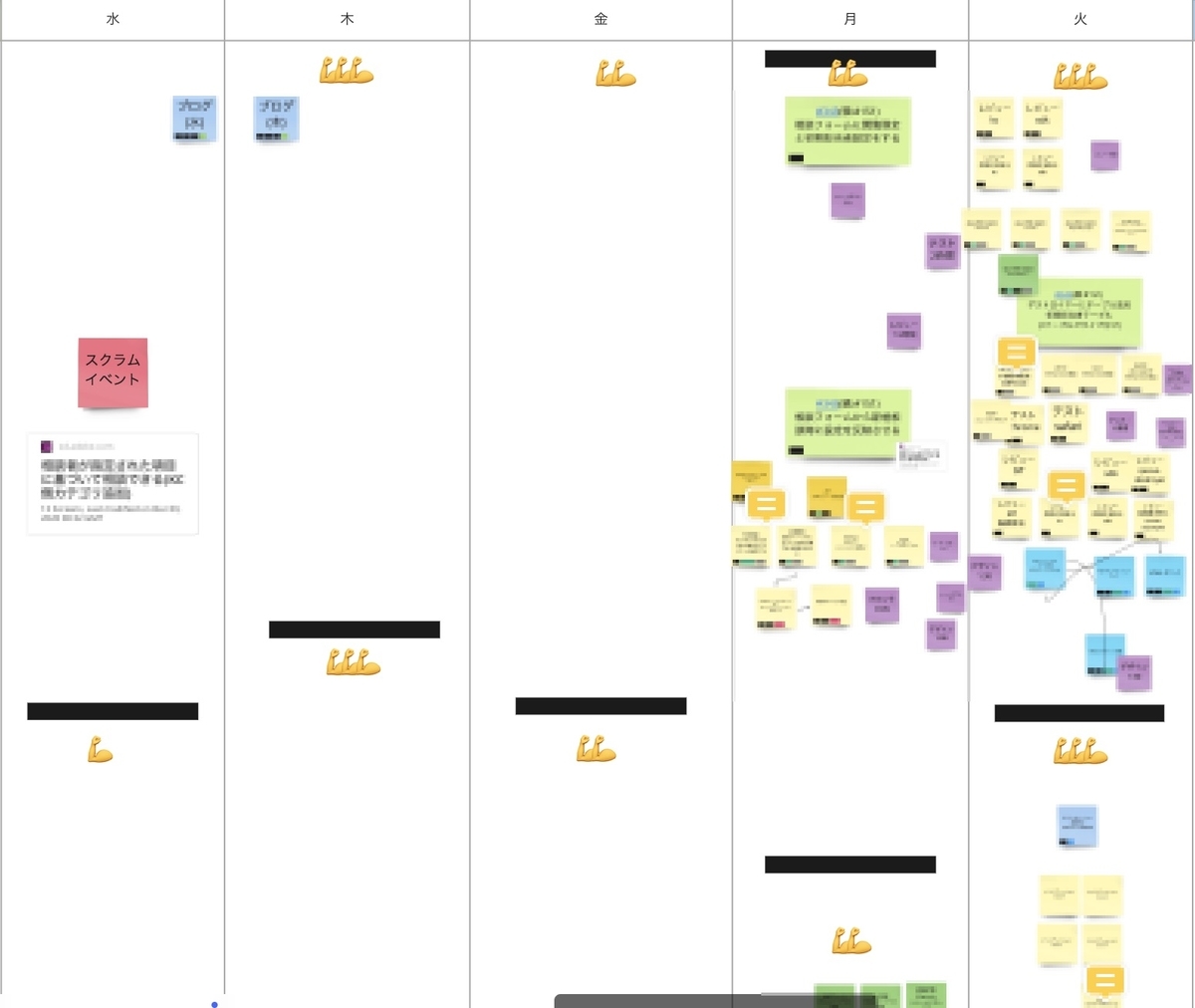
一通りの作業を洗い出したら、各曜日の午前午後に自分たちがスプリントに集中できるかどうかを一見してわかるようにマッスルマークというものを振っていきます。力こぶのようなものがそれです。下記画像参考
クラス名決め
さらにプランニング時点で想定できるクラス名を決めてしまいます。 ここで決めれば都度都度悩む必要がなくなりますし、誰でもすぐに作業に着手できるためです。
SBIの時間ふり
このあと、各付箋に予定時間をmiroのタグ機能を用いて設定していきます。 これによって、各曜日に置く付箋の量などを調整しやすく、 スプリント内における残タスク量も可視化しやすくなり、適応を促進してくれます。
ロードマップ調整
時間まで入力を終えるといよいよ最後にロードマップ決めとなります。 これまで洗い出した付箋にかかれた情報とカンバンをもとに、 一週間の中でどのようにスプリントゴールを達成するかを決めます。
スプリントゴール最終確認
ここで仮に想定していたスコープでは難しい・違ったといった気づきがあれば、量の調整やスプリントゴールの調整を行います。
以上が、スプリントプランニングトピックでHudsonが行っているものです。
まとめ
ガイドラインが新しくなり、自分もチームで一緒に読める機会が持てたのは非常に良かったです。 他のセクションに関しても、チーム内ないし開発内での読み合わせを行っていきたいです。
また、今回のワークでスプリントプランニングに対する共通認識を作れましたが、今後の経験を通してこのアジェンダも変化していくことと思います。 さっそく、定義後のスプリントで実践してみて、トピック3で時間が足らないなどのこれからの課題も見えてきています。
定期的にどういったプランニングをしているか続編としてブログにしたいと思います。
Holmesでは、スクラムを用いながらプロダクトを成長させ、契約に関する顧客課題解決を通じた価値提供をしていきます。 興味がある方はご連絡下さい。